I have already addressed the implications of modern LLMs, specifically their training, in the context of copyright and licenses for both code and original content. A 'IANAL' disclaimer applies to this post, but my honest opinion is that such training is a legitimate type of reading and learning after study, unless explicitly excluded in licenses among the licensee's rights.

Following the exploitation of LLMs and the AI boom that began in 2022, several lawsuits and litigations emerged among multiple parties, with a few reaching a significant milestone through the first court rulings. Note that every country has a bit different regulations about copyright and fair use, so the current lawsuites could be only the starting point of a long list of legal actions.
While most of the current lawsuits seem to demonstrate that Anthropic or Meta had the right to use books bought (in paper or digital form) for LLMs training (on the basis of the fair use principle), the most problematic aspect instead is the apparent use of pirated books taken from LibGen and other known piracy websites, which - if confirmed - can result in potentially destructive damange for the companies, to compensante authors and pay fees in the order of hundreds of billions.
The same problems are present in the coding parts: again, using FOSS-licensed code for training could fall under fair use, but training using private codebases, as well as proprietary ones, could be equally destructive for the same companies, as well as for GitHub and Microsoft. The key point would be demonstrating, without any doubt, the unfair use of private or pirated content, of course.
Of course, I'm quite sure future licenses for FOSS codebases and documentation could include an explicit exclusion clause for AI training, which could jeopardize the legitimation of use even for future FOSS code. I would expect such a license change, as some projects already explicitly exclude AI-based contributions. My opinion about such a question is that it could represent shooting oneself in the foot, due to the pervasivity of AI tools among developers currently. Adoption of AIAD could represent a boost in development time if adopted with a healthy dose of skepticism (i.e., a human-in-the-loop approach). About that, I'm quite convinced of Linus Torvald's point of view: the point is not who writes the code, but who is technically responsible for it and ensures the required quality review and supervision.
Moreover, an implication of the current polarization in the AI hype is the future (present?) crisis of traditional web content providers. A symptomatic case is the StackOverflow crisis, which will, with high probability, lead to the end of the service as we know it in the near future.
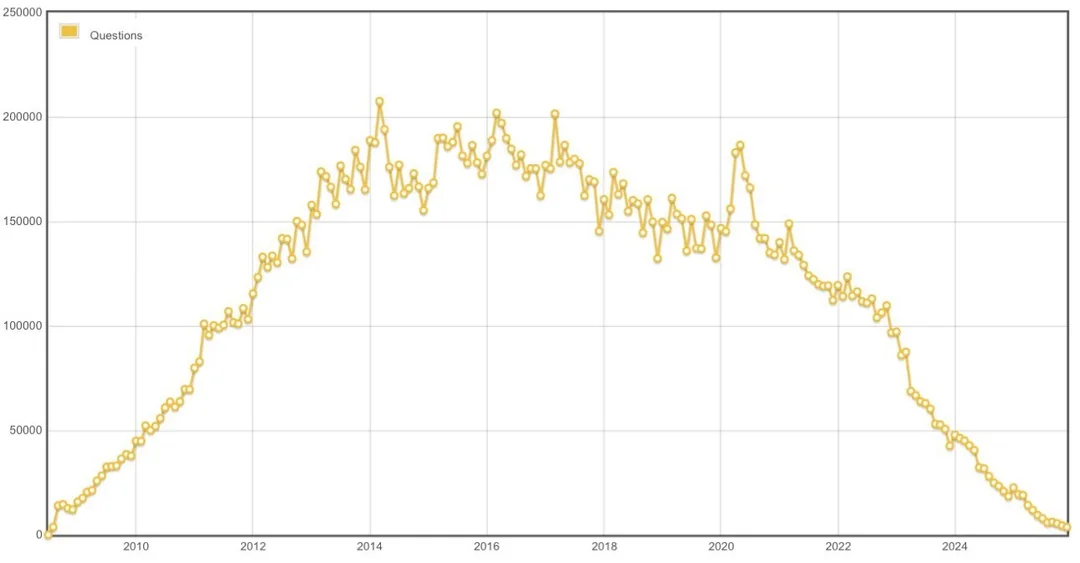
That will have an impact on future AI training, too, for sure, because SO has been for years a huge source of knowledge about multiple fields in IT. What if fewer and fewer people will contribute to Wikipedia and general web content? What if more and more sources of information were to reserve the right to use their information for pure human-driven study? Knowledge has not been static in human history; AI models will need to continuously enrich their training sets and stay up to date.
It would be grotesque if the whole AI hype were brought to a halt by such copyright-based legal questions (even if I'm pretty sure a fully fair training would be possible now for such companies, who knows the impact of a more limited approach on the final result?). Surely, this seems the most serious threat to the future of such companies and the whole AI-based solutions.
The only true solution to such a threat is finally having a true open training model, which details sources and the whole process of training with full transparency, something that even the so-called open AI models are still far to be ready to provide.
For comments, join the discussion on Mastodon.